
To estimate or not to estimate? Is that the question?!
To estimate or not to estimate? Is that the question?!

José is a new engineering manager of a team that has been using story points to estimate their work and make commitments to iterations. José observes early on that spilling over work from one iteration to the next is a common pattern.
Being a data-driven guy, he goes on gathering more insights on what has happened in the past. He eventually finds out what seems counterintuitive on its face:
It turns out that there's a tendency in which the smaller the estimated story points, the bigger the chance of spilling over from one iteration to another.
Put in other words, for some reason what should be the less complex parts of the work are the very ones often never gotten to. Being estimating a well-established practice in the team, and assuming (and there's no good reason to not do so) it's based on the best knowledge judgment of the team, it would seem indeed counterintuitive – but it's not really the case. The problem is precisely something else, the fact of being fundamentally operating with assumptions.
José at some point happens to meet a colleague, someone with experience on the matter, and they discuss what is going on with José and his new (inherited to be more precise) team. His colleague offers some perspective:
Here are two propositions for you to consider: first, obviously the fact of having spilling over is just a sign of overcommitting to iterations. Now, once you realize that, then maybe the fact that the smaller ones are the ones suffering to be done, it's not that counterintuitive, it's just a sign that the team is logically focusing first on the bigger chunks (as possibly the main parts) of the committed work, but then not getting to those smaller ones.
After a couple of back and forward discussions, Jose's colleague also offers a reframing of the problem, since it's clear that José is tending to approach the issue as one where the team needs to get better at estimating. Despite being slightly skeptical at first, José eventually accepts the offering, so his colleague goes on to explain some basic principles:
Story points are nothing else than throughput plus an assumption, and one that is in fact given upfront. And we are documented for not necessarily being great at it, on the contrary.
Throughput is something real, it is what happened, and thus already has embedded inherent variabilities like impact of dependencies, and whatnot.
Because of the inherent variability, we can be better off adopting a probabilistic mentality to deal with the underlying questions, e.g.: How much could we do in the given time frame? When might it be ready? How confident are we with the current plan?
José is in general fine with the idea, but he still insists on seeing some value in story points estimation, as a means to the team to discuss differences in understanding which are surfaced by the differences in estimating. That's one of the values of some sort of relative referencing like story points indeed – although one could argue that there are other tactics that can be used to ultimately fulfill the same hidden goal: discuss what assumptions are being made by whom… Jose's colleague keeps that "fight" to another day, and they agree to continue with the experiment of using throughput to forecast (as opposed to story points estimation and velocity), while not entirely dropping story points estimations altogether. One step at a time…
José gathers the data of weekly throughput stories for the last 21 weeks and prepares a histogram with the distribution of how many stories are delivered per week with what frequency. As his colleague had expected, the distribution visually indicates roughly a Gausian or normal distribution (so-called bell curve), with most often the weekly throughput ranging from 4 to 9 stories. That is relevant because it indicates that average is somewhat a trustworthy indicator (which can be confirmed by the closeness of it with the median: 7 vs 6.5).
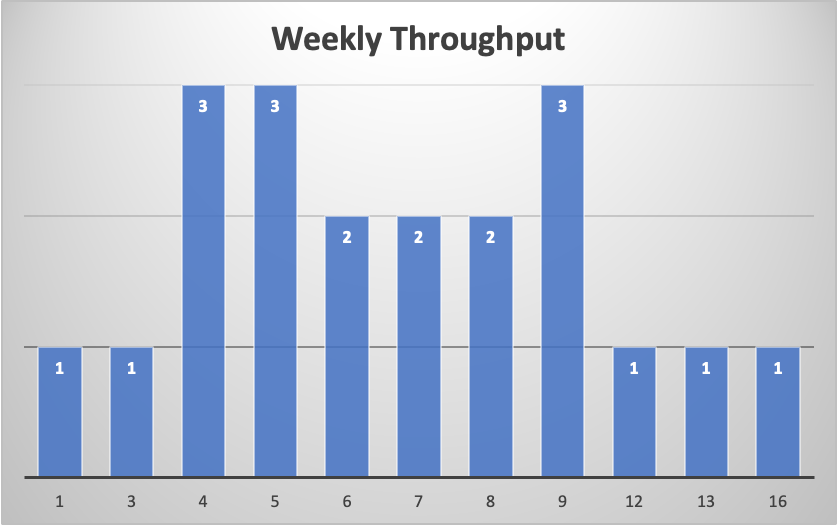
José's colleague uses that first observation to share an insight:
What this is telling us is that if you are OK being as confident as flipping a coin (i.e., 50-50%), then you use the average (or median) as a reference to forecast how much work the team can get done on a weekly basis (or whatever time frame you want to forecast ahead).
José is a smart guy though, so he thinks that leaving it at a flip-of-a-coin confidence level is not good enough. He asks for more guidance from his colleague accordingly. That's when he's introduced to the concept of percentiles as confidence levels, with the caveat that when it comes to a variable like throughput, you have to think of it in a mirrored fashion, e.g.:
A percentile 20% actually translates to a 80% confidence (or probability) of accomplishing up to that much work.
That led José through a whole journey of adopting throughput distribution patterns and probabilistic forecasting. He never again only blindly extrapolated a number based on average or anything like that, but rather taught his teams to even communicate in a way that let explicit the confidence level and thus how much risk they were carrying. With that, teams could unlock a whole new level of conversation on the questions that matter in the end:
e.g.: How much could we do in the given time frame? When might it be ready? How confident are we with the current plan?
The last trick he would learn from his colleague was that forecasts were dynamic events, not one-offs. And that reinstating plans wasn't a shame, but rather a way to embrace and communicate complexity. Things get simpler when that happens.
Needless to say that over time eventually that team stopped estimating work with story points. They instead started focusing on joint breaking down of the work (e.g., how many stories could this piece of work have, give your take?) that also occasionally surfaced different assumptions being made, and a conversation could follow.
To put it bluntly:
It's ultimately the difference between going with (at best educated expert) 'opinions' (with story points) versus a 'probabilistic forecast' that is founded in data and statistical distributions.
By Rodrigo Sperb, feel free to connect, I'm happy to engage and interact. If I can be of further utility to you or your organization in getting better at working with product development, I am available for part-time advisory, consulting or contract-based engagements.